



I’m using this series on dynamical models as a kind of walking tour of one aspect of knowledge creation. On the basis of a fairly deep look at a narrow set of data I’ve formed some ideas about what’s important in covid viral dynamics. This week is about shaking those up, because shaking up prior beliefs makes it easier to change them when confronted by contradictory data later on. When you encounter contradictory data, it’s often a good idea to step back and have another look at the path that got you there, rather than get too deeply into it right away: that gives you a better look at the overall landscape, which makes the contradiction more interesting and less annoying.
I've spent a lot of time modelling Canadian hospitalization data. My focus has been restricted for several reasons: I'm Canadian and I care more about what happens here than elsewhere. Hospitalization data are plausibly less biased and have less time-dependent bias than other measures of disease prevalence. And the Canadian data have very nicely distinct and regular peaks that suggested relatively simple dynamics are at work.
Getting intimately familiar with a single case of something can be a very valuable way to focus one's limited attention and resources so they do the most good. Understanding takes time, and often a deep dive into a single case is the best way to get a preliminary grasp on a subject. The risk is that you can end up taking ideas generated from that preliminary look way more seriously than they deserve when you start looking at the larger dataset. Things that seemed to make sense maybe no longer will and that creates a motive to not take the contradictory information seriously. After all, wouldn't it be nice if the contradiction were false or somehow bad?
The mathematical proof that Bayesian updating is the only way of knowing is driven by the condition that we must have an updating scheme for our ideas that doesn't depend on the order in which information is received. Finding fact A followed by fact B should lead us to the same plausibilities as finding them in the opposite order (if we start from the same place). A moment's reflection will suggest that we aren't very good Bayesians--at least I'm not--but being aware of a tendency to privilege the information we got first can help reduce this bias.
To help avoid that bias I'm going to look at other countries in a couple of phases. This week I'm going to take a high-level look at the characteristics of covid data in countries that report hospitalized patients. Next week I'm going to model the countries that look most like Canada, and the week after that I'm going to ask what's going on with the others.
The process of stepping back and taking a high level view is meant to be kind of "disorienting", in the sense of disrupting the path of thinking I was on. It loosens up the landscape, making subsequent re-orientation less painful. Just like exercising our muscles, exercising our brain can produce soreness, but warming up properly can help reduce it to more easily bearable levels.
On the basis of the Canadian data I've argued that omicron has a time from exposure to infectiousness of about 3 days, from infectious to recovered of about 7 days, and from recovered to susceptible again of about 34 days.
The first two numbers are fully consistent with the easily measurable data that epidemiologists and physicians have produced. The third number is quite a bit shorter than most estimates for waning immunity.
My contention is, based on the model, that most of the features of the data are explained by the nature of the virus, not the population. Population dynamics are only represented in the model by the value n, which is the number of people the average person comes into contact with (breaths the same air as) each day. Based on theoretical populations, I set this value at 20 for the average person, which is all my simple SEIRS model is concerned with.
Bayesians are interested in knowledge. We don't have to be smart--I'm not, really--we just have to be relentless. When we get an idea, when we draw a conclusion, we play the game of "If this is the case what else is the case?"
Bayesians actively test ideas against reality and update their beliefs accordingly.
The idea I have, in its most extreme form, is "Viral dynamics cause the case curves we see."
If viral dynamics rather than population dynamics cause the case curves, then we should expect similar case curves in other countries.
So I had a look. It would be lazy, unintelligent, and complacent to have an idea like this and simply stop after finding an apparently confirmatory case. Whenever that happens, you should immediately distrust the person doing the analysis: knowledge is created by testing ideas against systematic observation, controlled experiment, and Bayesian inference. The discipline of doing this is called "science".
If you get an idea and don't test it, what you've got is more bias and less knowledge. We want to tilt the scales away from bias, toward knowledge. There will always be some bias, but who cares?
Consider: every heat engine ever built has some losses--that's what the 2nd law of thermodynamics tells us--but nobody ever said, "Heat engines are useless because none of them is 100% efficient!" There are always losses. Getting them to zero is impossible. So what? Knowledge is the same: there's always some bias. Less is better. Getting to zero is impossible. Who cares?
When I went looking for other countries to test against I found that reporting on testing of patients in hospital for covid is fairly rare. I was only able to find a dozen or two countries that do it, and some of those stopped last year, or didn't start until well into the omicron phase. I also excluded countries the small populations, like Iceland, where the data are likely to be noisy. Typical values of a few hundred people in hospital per million gives a few dozen people total in a country with a population of a couple of hundred thousand.
Looking only at the countries that have data that is current to the past few weeks, I found the following list: ITA (Italy), CHE (Switzerland), JPN (Japan), BEL (Belgium), DNK (Denmark), ISR (Israel), GBR (Britain), CAN (Canada), NLD (Netherlands), AUS (Australia), IRL (Ireland), ESP (Spain), USA (duh), SWE (Sweden), FRA (France).
That's 15 countries. As I said a few weeks ago: looking at the data is a vital part of any analysis. For all that I knock our biases and cognitive distortions and failures, nothing can replace the Mark I Eyeball when it comes to preliminary analysis. It's easy to mislead yourself, so you have to be hyper-willing to discard any "eyeball hypothesis" that fails rudimentary testing, but there is no better source of preliminary understanding than simply looking closely and carefully, and it helps you avoid drifting off to the land of floating abstractions.
And when you find a conflict between your eyeballs and an algorithm, the process you embark on is to discover the source of the disagreement, not "prove one or the other side right."
You also have to be very careful not go to "hypothesis chasing" in this process. It's easy to look at the data selectively in ways that seem to confirm your biases. Having the discipline to not do this, and to turn around and test that idea to destruction when you catch yourself at it, is part of what makes data analysis difficult. If you do find yourself hypothesis chasing you know you've found a sore spot where you're trying to protect your ego. Don't do it. Your ego is robust. It'll still be there when your favourite idea is knocked down. Just as in life chasing what makes you afraid is often a good growth strategy, in knowledge chasing what gives you a sinking feeling is almost always a good analytical strategy.
This is one of the reasons why promises that you can "learn data science in ten hours!" are unlikely to be honest or accurate. Science is like any other discipline. Can you learn karate or tai chi in ten hours? Not a chance. Disciplines worthy of the name take years, maybe even a lifetime, of regular, deliberate, practice. And without practice they fade away. Put someone behind a bureaucrat's desk for a few years doing nothing but generating paperwork and grant applications and they will fall out of the discipline, just as surely as a martial arts practitioner who stops practicing will. The world is full of "wasting skills" that decay if they aren't regularly reinforced. The disciplines of Bayesian thinking are like that, because they are profoundly unnatural: use 'em or lose 'em.
As is typical of data collected under quite different conditions--every country will have its own protocols and biases--the different country data are a bit of a mess. Some only report weekly, some--like Sweden--seem to have shifted from daily reporting to repeating the same value seven days in a row around the onset of omicron, and so on. Untangling this mess creates room for biases to go dancing all over the place. We want to try to avoid that.
The first thing I did after looking at all 15 curves was to run a little bit of automated peak and dip detection to get a sense of the spread in the data. Pulling peaks out of the Canadian data by hand gave me an 88 day spacing between peaks, which falls in the middle of the automated results:

I've plotted both peak and dip spacing, and excluded six countries where my dumb-as-rocks peak detector didn't work well. Japan and Britain only report once a week with zeros everywhere else. Several countries had too few peaks to analyze, which will bias the result and so must be revisited. Other countries changed their reporting from daily to weekly in the middle of omicron, and Sweden is just weird. More work could fix these issues, but time.
The value of simple automated extraction is that for the countries where it works it gives a reasonably unbiased result, and while the average spacing is scattered around quite a bit--biology is like that--the values centre on the ones found in Canada, which suggests that viral dynamics do play a big role.
For the cases where the peaks are reasonably well-behaved, something interesting happens when I align the first omicron peak and plot the case curves--normalized to population--on top of one another:

It may be an illusion—if you take France away I think most of the effect vanishes—but it may be the higher the case numbers, the shorter the distance between peaks. This is what the SEIRS model predicts, and may be a result of n, the average number of contacts per day: the faster the disease spreads, the shorter the distance between waves.
This bears more investigating, and I'll take a shot at fitting the SEIRS model to these data and see what falls out. My bet is that higher n*p values can explain these differences with the viral time parameters fixed.
Then there are the other countries, where the data aren't very much like Canada or anywhere else. The Canada-like countries are: CAN, IRL, FRA, ITA, GBR, and AUS. Of the other countries, BEL, DNK, CHE, ESP, and NLD are not totally dissimilar to Canada, but have one peak out of place or odd peak magnitudes, which may reflect either population or viral dynamics: while we've settled down into a relatively homogeneous "variant soup" today, the first six or ten months of omicron saw different variants rise at different times around the world.
A new variant can result in a "displaced peak" as it sweeps a country out of step with what happened elsewhere, and violating the model assumption that the viral dynamics stays fixed, because new variants are typically both more infectious and able to escape even the short period of immunity prior infection gives. It's notable that in BEL, DNK, NLD, ESP, and CHE the spacing of peaks is roughly consistent with the majority other than a single anomaly, and ESP has peaks that are correctly spaced but with odd magnitudes.
That leaves USA, SWE, ISR, and JPN as absolute outliers.
In Japan, maybe population dynamics matter. Japanese people wear masks and behave like civilized human beings, at least with regard to the pandemic. This may have contributed to longer waves there. Or not. It’s just one possibility.
The Swedish data are strange in a couple of ways: as well as the apparent shift from daily to weekly reporting, there is period of over two months where the number is a constant, for example. This gives me concerns about the quality of curation in Stockholm [edit: in the voice-over you’ll notice I say “Olso” because geography is apparently not my strong suit.]
The US and Israel have pretty clean data and see much longer waves.
On closer inspection, the four nations that don't fit the Canadian model at all (USA, SWE, ISR, JPN) differ in that they have only three peaks in the omicron era, and seem to be missing the second peak that the other 11 nations in this dataset have:
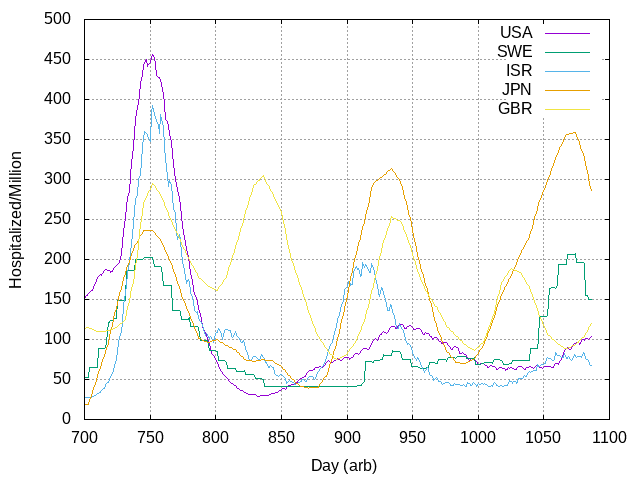
It took me a lot more hours than one might imagine to break down the data in this way. Finding a core set of "Canada-like countries," understanding the dimensions the outliers lie along, and then processing the raw data so that the first omicron peak lined up for all countries was required before the larger patterns started to really come into view. Focusing in on the role of the "second peak" (or its absence in the four "three peak nations") explained a lot: it's early in some nations (BEL) and late in others (CHE). Why this should be so remains an open question.
The fact that two-thirds of the nations with relevant data have a similar pattern of peaks tends to support the idea that viral dynamics matter much more than population dynamics. Canada and Australia almost certainly have different population dynamics than Belgium or France or Italy, but show the same pattern of peaks.
The existence of four outlier nations all of which are very similar suggests that something other than viral dynamics is at play in those cases.
This is what makes searching for knowledge fun. Or at least a full-time job.
It may be that major differences in population dynamics in the form of higher or lower contact rates, or something about the detailed structure of the population, can result in significantly modified case curves, but for the "average" developed nation (almost all these data are from Europe) viral dynamics dominate the case curves.
The next reasonable thing to do is to run the model fit for every country I can in this extended data set, and see if a fixed set of viral parameters but variable n*p and hospitalization fraction can explain the differences.
Stay tuned!