


What Can a SEIRS Model Tell Us About Covid?
the parameters of the pandemic

What do the SEIRS model equations tell us about the covid pandemic?
Remember, while the model involves a number of simplifying assumptions, it is orders of magnitude more sophisticated than the most complex informal understanding, which cannot scale beyond a few approximate factors.
Human cognition can get a lot of mileage out of conceptual reasoning, but first we need something to reason about. A combination of data and modelling gives us far more than the data alone. Nothing else comes close, and imagination is antithetical to it: imagination gives us stuff to reason about that does not--and frequently cannot--exist.
The simplifying assumptions that have gone into this model include:
1) The population is treated as homogeneous. That is, everybody is the same in terms of the number of contacts they have in a day, their masking habits, and indoor air quality where they work and live, and so on. Adults, kids, seniors... everyone is considered the mythical "average person", which is, again a much better representation of reality than anyone's merely cognitive capabilities are able to come up with.
2) The time delays that describe the disease have no variance. All the people who are newly exposed on day X become infectious on day X+Te, recover on day X+Te+Ti' and become susceptible again on day X+Te+Ti'+Tr', where Te, Ti', and Tr' are the times spent in the exposed, infectious, and recovered states, respectively.
3) The disease dynamics do not vary with time. That is, infectiousness, waning immunity, and so on, are all constants. Nobody starts wearing masks or setting up HEPA filters or installing UVGI, all of which change the disease dynamics by stopping it in the air. As was actually the case for most of the omicron era, venues and event organizers don't do anything more than "strongly recommend" masks, which means: "Nobody wears masks."
Venues and event organizers who say, "But we told people masks were recommended!" as if that absolves them of responsibility, when they know that no one will follow those recommendations, are members of a libertarian cult who believe "personal responsibility" is the solution to all our problems.
I don't care what anyone's nominal politics are: if they're organizing events in venues without 6 to 10 changes of HEPA-filtered air per hour or similar upgrades (UVGI, displacement ventilation, etc), and are doing nothing but "recommending masking" they are as a matter of operational fact members of the hyper-individualist far right.
4) The population dynamics do not vary with time. Nobody stops seeing people or going out to eat in restaurants. See above, in re: libertarian cult membership.
These constraints are largely artifacts of the mathematical description. While it's possible to build a much larger system of equations that relax these constraints by creating a bunch of coupled sub-populations with different parameters, this greatly increases the model complexity. There are simpler ways to do it via a completely different kind of model--which go by the name of Monte Carlo methods--which I'll get to in future.
For now, we'll live with these limitations and see what we can learn. They aren't actually terrible approximations, at least insofar as it's possible to reproduce something that looks uncannily like the Canadian situation despite the model's simplicity.
The data I'll be using is Canadian hospitalization numbers. This has the advantage that in-hospital testing has been fairly consistent for the past several years, although as with any political, partisan, government, or corporate dataset we have to be aware of the possibility of bias.
The model is four simple equations, which I'll repeat here along with the following paragraph of boilerplate that you've probably read before:
dE/dt = S*n*p*(I/N) - E'[Te] (1)
dI/dt = E'[Te] - E'[Ti] (2)
dR/dt = E'[Ti] - E'[Tr] (3)
dS/dt = E'[Tr] - S*n*p*(I/N) (4)where E, I, R and S are the number of people in the Exposed, Infectious, Recovered, and Susceptible states, Te, Ti, and Tr are the number of days from Exposure to Infectious, from Exposure to the end of the Infectious phase, and from Exposure to Susceptible again. N is the total number of people (thirty-eight million in the case of Canada), and n*p*(I/N) is the individual probability of getting infected each day, which when multiplied by S (the number of susceptible people) gives us the number of newly infected people. n is the number of people someone encounters each day, p is the probability that an encounter with an infected person will result in infection, and I/N is the probability that anyone a person meets is infectious.
The Law of Conservation of People means the past determines the present: the number of people transitioning from one state to another today depends only on the number of people who were newly exposed some fixed number of days in the past.
For all that I've emphasized the importance of numerical representation, the first step of any data analysis is always to look at the data. This can be complicated and time-consuming. For multi-dimensional data it can involve generating "slices" through the high-dimensional space. On more than one occasion I've spent hours or days paging through individual events using custom-built visualization tools trying to see patterns. Getting up-close-and-personal with the data is absolutely vital to making fair and informed choices about how to understand it.
In this case, the data is simple, just the number of Canadians in hospital with covid on any given day for the past three years:

This dataset can be downloaded from the Government of Canada, which is fortunate because the big global aggregator at Johns Hopkins is being shut down in March, which will blind most of the world to what's happening.
This is a very bad thing, because access to the data is a human right when the data can be reasonably easily collected and could reasonably be used to inform policy decisions by any level of government. A government that could reasonably collect data that could be reasonably used to inform policy and doesn't or doesn't publish it is violating human rights.
The data is scared. It allows us to know reality. Nothing else does.
Looking at the data, we can see two eras: before and after omicron. The first omicron wave starts around day 700, which is in early December 2021. After that there is a series of more-or-less well-defined peaks and dips over the next year, which start to blur into each other after the third peak, although there is a pronounced dip in the recent data that we are now starting to come out of.
This suggests that while the omicron waves are diminishing, they are not quite yet done. The modelling work I describe here is aimed solely at the omicron era: what came before involved changing variants and sometimes-effective public health interventions, like mask mandates, that make modelling much more complex and a good deal less informative.
The model has a bunch of parameters, but only three of them have much freedom: the time over which immunity wanes (Tr'), the encounter fraction (n), and the probability of infection (p). The average time between exposure and becoming infectious is strongly constrained by the data to around 3 days, and the average time a person is infectious is likewise fairly well-defined at around 7 days.
Modelling of theoretical populations as well as personal experience puts the average number of encounters per day in the range of 10-30, which is a fairly well-defined range, and we know immunity wanes on a scale of months, not days or years, although as we'll see the model suggests it's shorter than generally believed.
The infection probability is the least well-known parameter, as knowing it depends on either extremely detailed case follow-up or competent modelling of the case data by epidemiologists. My investigation of the epidemiological literature thus far does not encourage me on the latter point [sorry], and observation of the incompetence of provincial public health authorities in Canada does not encourage me on the former. So I went into this modelling exercise with an open mind about infection probabilities.
Because the infection probability per encounter (p) and the number of encounters per day (n) only appear in the model as their product (n*p) the value of n has to be fixed, and a higher or lower value of n will result in a proportionally lower or higher value of p. I've chosen n = 20 as the mid-range of plausible estimates, but keep in mind that the value of p extracted from the model has the uncertainty in n folded into it.
Having data and model in hand, I proceeded to play around with the model, and found I could generate a wide range of scenarios with fairly small tweaks to the parameters. This is a known phenomenon with SEIRS models.
The scenarios fall into three general types:
1) Eternal peaks: the model generates an infinite series of sharp peaks with very low minima between them. This tends to come from longer waning times, as the basic dynamics are: everyone gets sick and becomes immune so the rate of new infections drops off to almost nothing, then everyone becomes susceptible again and we're off to the races.
2) Die-off: there is a peak followed by a fall to zero. This is associated with lower encounter rates and lower infection probabilities, as the pandemic simply isn't sustainable. This allows us to say that for sufficiently good mitigations, we can kill covid in the human population.
3) Plateaus: a series of peaks of decreasing amplitude that converges onto a plateau. This appears to be the scenario we actually have. If the plateau is low this is called an "endemic" state. If the plateau is high--for example if the disease persists as the third biggest killer in the country--it is called a "hyper-endemic" state.
Next week I'll look into the different scenarios in more detail, and how they can tell us about the range of plausible parameters. For now I want to focus on the parameters that most closely approximate our reality.
The data are noisy, and more complex than just a series of smooth peaks. This is a situation where Aristotle's dictum that "the student ought not to expect more precision than the subject matter admits of" is very much on-point. On the other hand, the simplicity of the model means it is much easier to understand the primary drivers of the disease dynamics. We aren't trying to match every small bump and wiggle in the data, we're trying to get a general sense of what's causing the number of cases over time.
It's not people going on vacation or kids returning to school. We can say that right off, just looking at the data.
It's the viral dynamics, which is precisely what the model is, err, modelling.
One thing that jumps out at you when looking at the data is that there is a lot of power in the first couple of peaks, and so to focus in on the parameters that give the best fit between the model and reality I did a brute-force comparison between a few numbers that characterize the data and the model output.
These numbers are: the average peak spacing for the first four peaks (insofar as I can estimate them from the data), the ratio between the peak height and the following dip for the first two peaks, and the ratio of the second peak to the first peak.
This was enough to get me roughly in the right ballpark in terms of parameters, which I then used to run a non-linear minimizer comparing the model to the data. This resulted in a pretty reasonable fit:
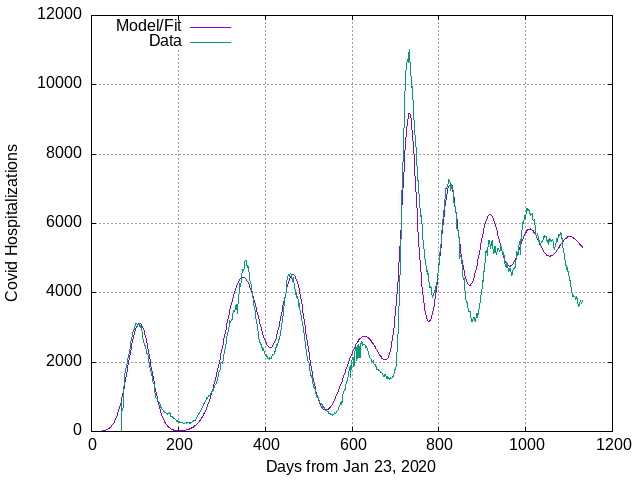
Prior to the omicron era I'm just fitting some Gaussian peaks, which have no dynamical significance: they just allow me to extract parameters like peak area and width, as I've talked about previously.
The omicron era, after about day 700, is a fit to the SEIRS model with just under 3 days between exposure and becoming infectious, just over 7 days for the infectious period, and a little over a month (34 days) between recovering and become susceptible again. The value of p, the probability of catching covid from someone you encounter who is infected, is just over 1% (p = 0.0117) and the fraction hospitalized is just 0.2%.
There is also a nuisance parameter which is the shift between the model days and the data days: the model starts at day 0, which is equivalent to about day 687 in the data. This shift is not part of the fit, but is found by looking at the first model peak and setting the shift so it aligns with the peak in the data. The precise position of the model peak varies with the other parameters, so this is done on-the-fly.
Several of these values are surprising.
The time to waning immunity is lower than expected, but I can't get anything remotely resembling the 88 day spacing between peaks that we observe in the data if I change the time to resusceptibity. The best fit gives a 92 day average spacing, which is well within error given the challenges of extracting anything but the first two peaks out of the data. To get 88 day spacing I actually have to reduce the time to resuscepibility to 31 days from 34. If I increase the waning time to a month and a half (47 days) the peak spacing goes from 88 days to 120 and the comparison of model and data looks like this:

The second peak and following dip are miles off in this scenario. Either the model is wildly wrong for some reason—not impossible, but any critique needs to identify specifically what the problem is—or covid immunity wanes in about a month, either due to new variants in circulation, or the simple fact that no human being anywhere has ever become permanently immune to any corona virus, including all four of the corona viruses that cause common colds.
In terms of waning immunity, covid is just behaving exactly how you would expect a corona virus to behave, albeit faster than usual.
The other parameter that looks a little off is fraction of people who end up in hospital, which is low unless the number of people who are ill is higher than previous estimates. It turns out there is evidence for that, which I'll talk about later.
This is just a first pass at one aspect of the model results. Next week I'll look at what happens when we start to vary more parameters.
Dynamical models are the x-ray vision of complex processes: if we use them carefully we can see more deeply. Like any instrument, they are capable of producing a distorted view, but they will always be more powerful than the unaided imagination.
This model is telling us that covid immunity wanes rapidly, and it is likely that covid prevalence in Canada in omicron era is much higher than official numbers indicate, and that we are now in the hyper-endemic phase of the pandemic, and will continue to persist in it, with covid as the third-highest killer in the country, for as long as we continue to allow libertarian cultists to drive social policy on mask mandates and clean air.
Really nice work Tom
(Marvin)
Thank you again for giving insight into how to model and understand reality. I especially found it helpful to see how far off the model fit drifted from the data when the length of time to resusceptibility was increased.